This post is based on our recent paper: Faster and Memory-Efficient Training of Sequential Recommendation Models for Large Catalogs.
If you’ve ever trained a sequential recommendation model on a large item catalog, you’ve probably hit the GPU memory wall. The standard fix is cross-entropy with negative sampling (CE−): instead of scoring all items, you score a small subset of negatives. Simple enough. But here’s the question most practitioners never stop to ask how many negatives should you actually use?
The intuitive answer is “as many as you can fit.” More negatives means a better approximation of the full loss, right? Our experiments across six real-world datasets including Zvuk (893K items) and Megamarket (1.6M items) — show the reality is more complicated.
In fact, the question runs deeper than just negative samples. When working under a fixed GPU memory budget, you’re always trading off between three dimensions: sequence length (sl), number of negative samples (ns), and batch size (bs). Increase one and you have less room for the others. So which one should you prioritize? Should you max out negatives for a better loss approximation, use longer sequences to capture more user history, or go for larger batches for more stable gradients? We ran ~1000 training experiments across six datasets to find out.
Batch Size Is the Factor You’re Probably Underweighting
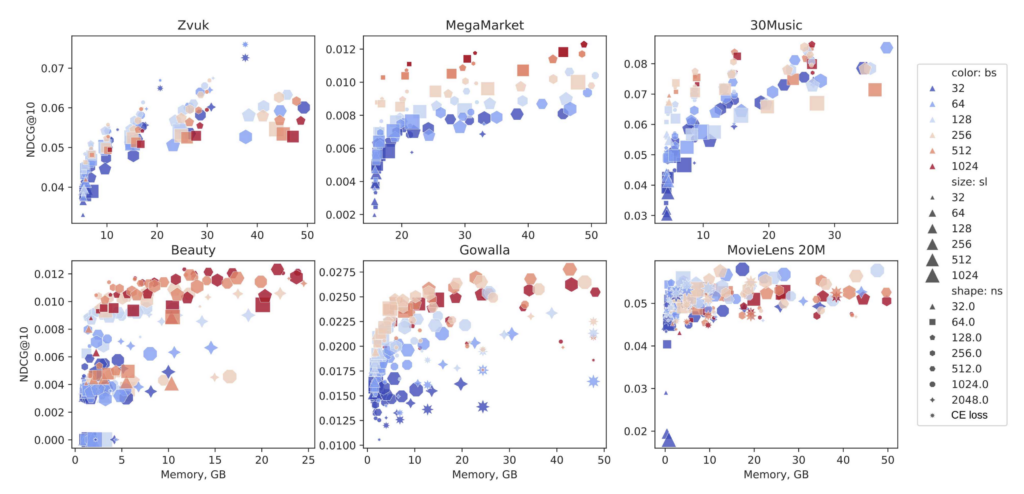
Memory scaling across three dimensions: batch size, sequence length, and number of negative samples across six datasets
The plot above visualizes roughly 1000 training runs of SASRec across different configurations of batch size (bs), sequence length (sl), and number of negative samples (ns). The takeaway is immediately visible: batch size is the dominant factor. Large batch sizes consistently cluster at the top of the quality chart, regardless of how many negatives were used. This holds across all datasets except Zvuk, where bigger ns is actually more important.
More Negatives Helps — Up to a Point
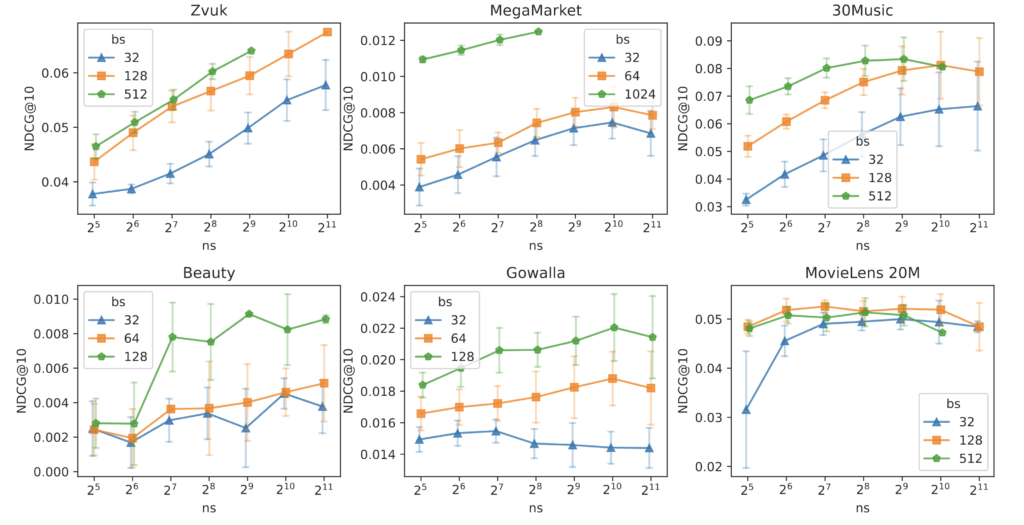
NDCG@10 vs. number of negative samples (ns), aggregated across sequence lengths, per dataset
Looking more closely at the relationship between ns and NDCG@10, performance increases with ns up to a certain threshold but then saturates or even slightly drops: MegaMarker, 30Music, Gowalla. For MovieLens, ns has surprisingly little influence at all.
It’s the Interactions That Matter Most
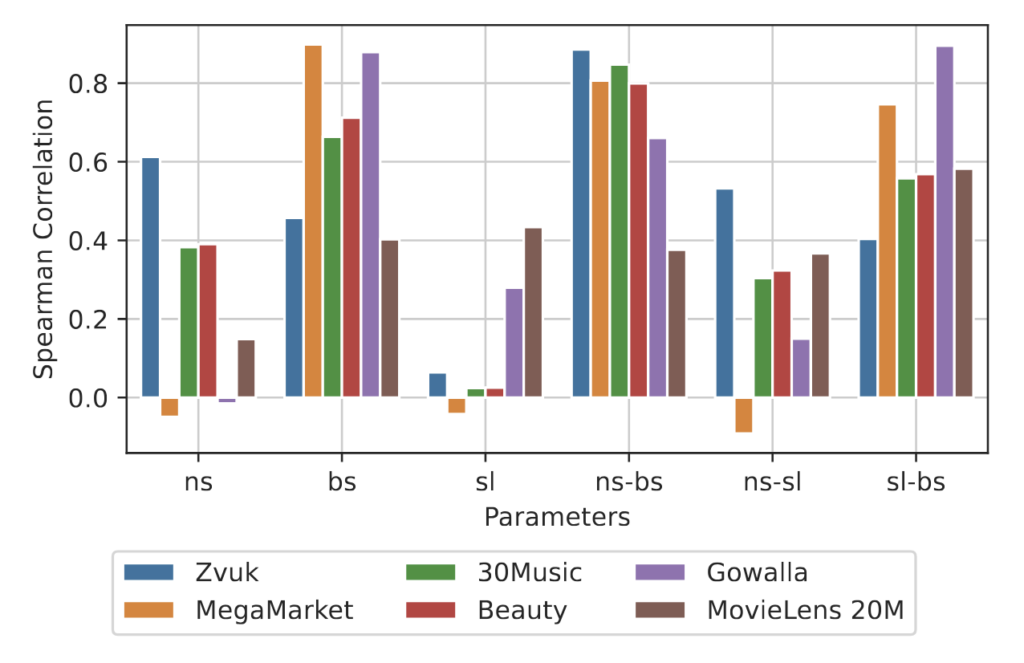
Spearman correlation for bs, sl, ns and their pairwise interactions
When we ran Spearman correlation analysis across all datasets, the picture became even clearer. Both bs and ns matter individually, but their interaction (bs×ns, sl×bs) matters even more. Scaling one dimension or while holding the others fixed gives diminishing returns, especially ns or bs have the least impact unless combined! The best configurations consistently came from balancing batch size and negative samples seem to be more important on average however, it all depends on dataset.
What This Means in Practice
- Very small ns (e.g. 32) leads to unstable, weak training across all datasets.
- Very large ns doesn’t always help and can hurt.
- A moderate batch size of 256+ with a reasonable sequence length will often outperform a configuration with 2048 negatives and a tiny batch.
- If you free up GPU memory, don’t pour it all into ns spread it across bs, ns simultaneously.
The full dataset of 997 training runs, covering every bs/sl/ns configuration we evaluated, is publicly available alongside the code at github.com/On-Point-RND/MemoryEfficientSRS.
Hi, thanks for the post!