A review of two papers from our colleagues at Sber AI Lab: DeTPP & HoTPP.
- What do we want?
To predict future user behavior — for example, generating purchase categories and timestamps. - The problems.
[1] This used to be solved via TPP methods, where we predict the user’s next event and its timestamp. But in practice, a single event isn’t enough. We could predict multiple events recurrently, but in that case our objective is still next-token-prediction, whereas what we actually want is next-tokens-prediction, right?
[2] Autoregressive methods assume that events occur strictly one after another, but people behave fairly randomly even if patterns exist — on any given day you might buy bread, pay a loan, and send money to your mom, all in a random order, yet the distribution of events within the day remains the same.
HoTPP
In HoTPP, the authors articulate all these problems and propose a new benchmark along with a metric called T-mAP for comparing such temporal distributions.
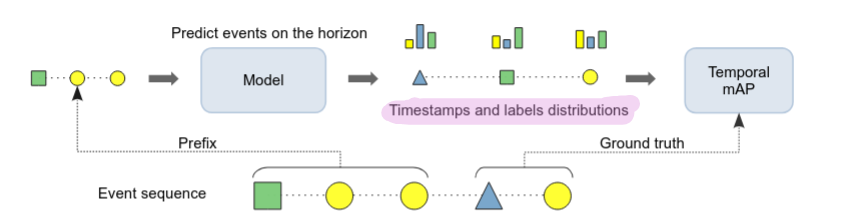
The T-mAP Metric
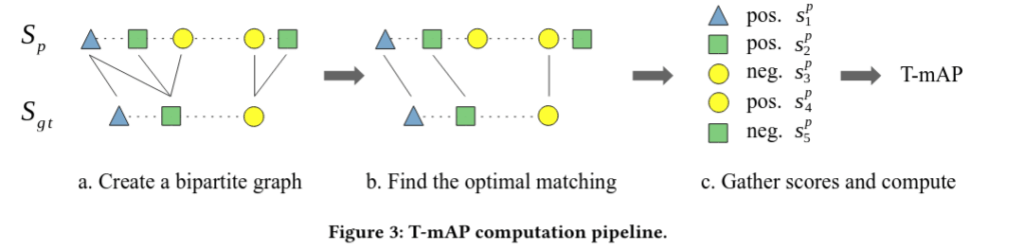
The metric combines three ideas:
- We sweep a threshold — similar to how RocAuc is computed — and observe how quality changes.
- We align our predictions with targets rather than comparing them one-to-one.
- For time, we introduce a left-and-right window
 — essentially dividing the time interval into buckets of size .
— essentially dividing the time interval into buckets of size .
The metric ends up with two hyperparameters: the prediction horizon and the time step size .
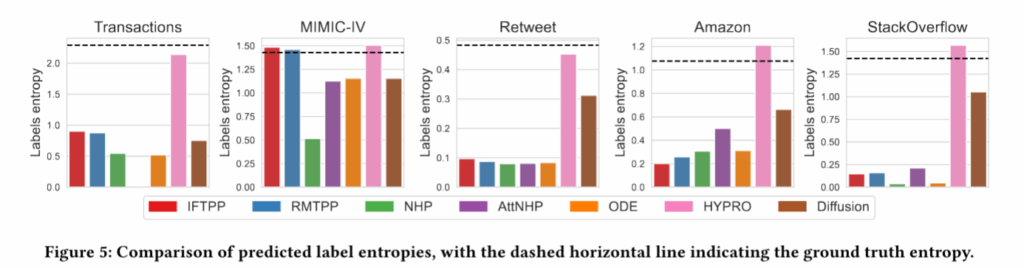
Results:
- Statistical baselines such as mode and history-based distribution land in the top 3 methods.
- Models frequently collapse to the mode. Autoregressive methods tend to have low entropy — focusing on a few specific, most frequent tokens.
- Methods like HYPRO and diffusion-based approaches perform best, though they were specifically designed for long-horizon prediction.
- Methods trained on the next-token-prediction objective perform significantly worse.
- The authors also show that standard metrics are not very sensitive to rare events, whereas T-mAP is considerably more sensitive to them.
DeTPP
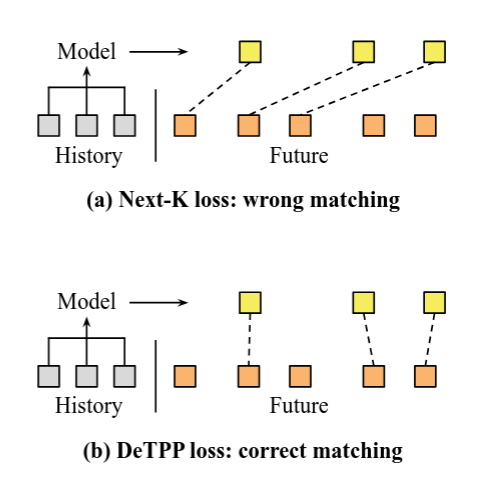
Naturally, once the problem is well understood, you can build a method to solve it. That is exactly what the authors do in the follow-up paper DeTPP.
The core idea: let’s train the model to align its predictions on the fly.
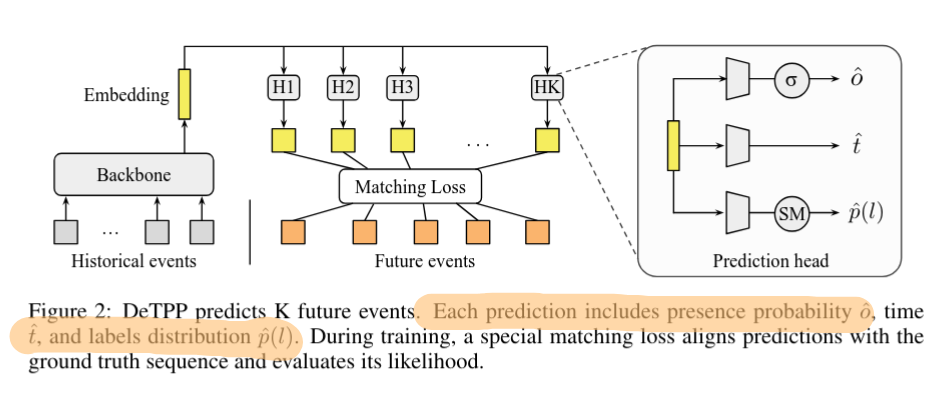
The final loss factorizes as: 
- The probability of an event occurring at a given time
 ,
, - The probability of an event occurring at all
 ,
, - The probability of the event’s category
 .
.
Once we obtain the predicted classes and timestamps, we additionally align them in a manner similar to the T-mAP metric.
The authors then describe several architectural decisions — which transformer components are used to predict each part — which I will skip here. The main hyperparameters are the prediction horizon and the allowable time shift (mirroring those of the metric).
Results
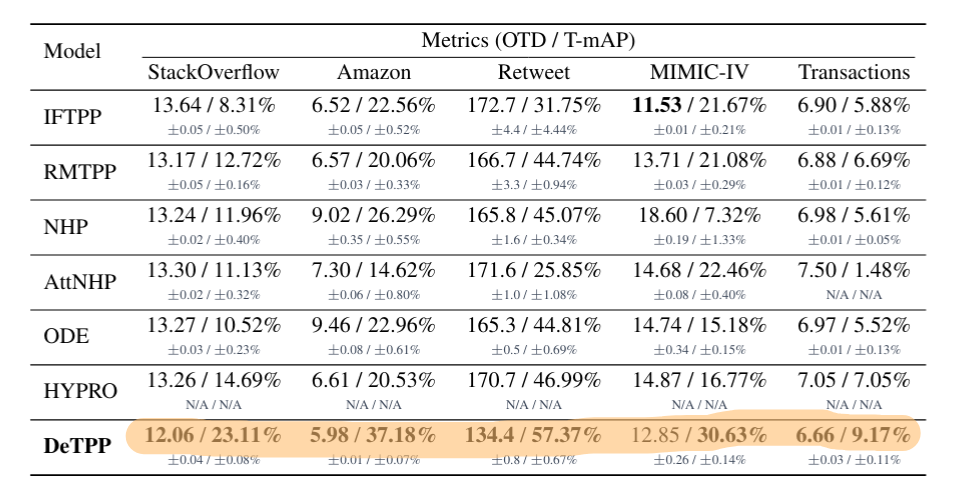
Everything performs as expected. Notably, this approach also works well for next-token prediction, matching methods that were specifically trained for that task.